Decoding Vector Databases: The Core of Generative AI’s Growth!
The field of Generative AI, a frontier in the artificial intelligence landscape, is rapidly evolving, continuously pushing the boundaries of what machines can create and comprehend. At the heart of this technological marvel lies an unsung hero — vector databases. These specialized databases are pivotal in managing the complex data structures that generative AI systems rely upon.
Unlike traditional databases, vector databases are designed to efficiently handle, store, and retrieve high-dimensional vector data, which is essential for powering advanced machine learning models. This article aims to shed light on the critical role of vector databases in Generative AI, exploring their foundational concepts, technological nuances, and the challenges they help overcome. As we delve into this topic, we will unravel how these databases are not just a backend utility but a driving force in the ongoing AI revolution.
The ABCs of Vector Databases!
In the ever-evolving world of technology, particularly in the field of artificial intelligence (AI), there’s a growing need to understand and manage complex data. This is where vector databases come into play. But what exactly are vector databases?
Imagine you have a large collection of photos, and you want a computer to sort and understand them just like a human would. Traditional databases are like meticulously organized photo albums, with each picture neatly labelled and categorized. However, when it comes to AI, particularly Generative AI, things get a bit more complex.
Generative AI doesn’t just sort data; it tries to understand patterns, create new content, and make decisions. For this, it needs to understand data in a way that’s more like how our brains perceive things, not just as simple labels or categories. This is where vector databases shine.
A vector database stores data in a format that AI can easily understand and use. Let’s go back to the photo example.
In a vector database, each photo is transformed into a “vector” — a list of numbers that represent all the intricate details and features of that photo, much like a unique fingerprint.
These vectors help AI to not only recognize photos quickly but also to understand subtle patterns and similarities between them.
In essence, vector databases translate complex, real-world data into a language that AI can efficiently process and analyze. They are essential for advanced AI tasks like image recognition, language processing, and creating new content, which is the heart of Generative AI. By using vector databases, AI systems can operate more intuitively and effectively, mimicking the human ability to understand and interpret complex information.
Here is the quick summary →
- A vector database is a type of database designed to efficiently store and manage vector data.
- Vector data, in the context of computer science and artificial intelligence, refers to data represented as arrays of numbers, often known as vectors.
- These vectors are mathematical constructs that can encode various forms of complex information, such as the features of an image, the semantics of a piece of text, or the characteristics of audio.
- Therefore we can say, vector databases are specialized databases optimized for storing, managing, and retrieving vector data, which is essential in various AI and machine learning applications. They provide a way to efficiently handle the complex and high-dimensional data that these applications rely on.
Vector DB Vs Relational DB Vs Non Relational DB
It is vital to understand the difference between various DB’s that are available in the field of computer science. Below table distinguishes vector databases with other available.

Vector Embeddings
Let’s start with the basics. First, I’ll explain what a vector is, and then we’ll talk about Vector Embeddings.
A vector is a math concept that has both size and direction. You can think of it like a point in space, with the direction being like an arrow going from the starting point (0,0,0) to where the point is in space.

When we look at a bunch of vectors in one space, we can say that some are closer to one another, while others are far apart. Some vectors can seem to cluster together, while others could be sparsely distributed in the space.
Hope you have understood the concept of vector. Now let’s proceed towards understanding the concept of → “Vector Embeddings”
In the field of machine learning (ML), a fundamental concept often encountered is Vector Embeddings, especially when dealing with non-numeric data. These embeddings are crucial for ML engineers as they form the foundational elements of numerous ML and deep learning (DL) algorithms. In this discussion, we will explore what Vector Embeddings are and how they are utilized in artificial intelligence (AI).
Vector embeddings are a way to convert words and sentences and other data like images or audio into numbers that capture their meaning and relationships.
Let’s take a look at below example -

In simpler terms, when we deal with text data, different words like “cat” and “kitty” might have similar meanings, but they are made up of different letters, so they look very different to a computer. To help a computer understand that these words are similar in meaning, we use something called vectors. Vectors are a way to represent things in the computer. They help to show the computer that “cat” and “kitty” are similar, even though they are spelled differently.
How Vectors are Embedded?
- For Text: Words or phrases are converted into vectors using algorithms like Word2Vec, GloVe, or BERT. These algorithms analyze a large corpus of text and learn to represent each word by a vector such that words with similar meanings have similar vectors.
- For Images: Techniques like Convolutional Neural Networks (CNNs) can be used to transform pixel data into vectors, capturing features like edges, textures, or more complex patterns.
Example —
Let’s walk through the process of converting a sentence into a vector embedding using a machine learning approach. We’ll use a simplified example to make the concept clear.
Sentence: “The cat sat on the mat.”

The above image illustrate the process of the creating vectors through the sentences. In similar fashion (with few changes here and there), the vectors will be created for image, audio etc.
Type of Vector Embeddings

Use-cases of Vector Embeddings
Vector embeddings are used in many domains. Let’s look at few example where vector embeddings are useful.
- Semantic Search: Traditional search engines match keywords, but with vector embeddings, semantic search understands and finds results based on the real meaning behind a query.
- Question-Answering Apps: By training a model with question-answer pairs, we can make an app that answers new questions it’s never seen before.
- Image Search: Vector embeddings are great for image search tasks. There are many ready-to-use models like CLIP and ResNet, each good for different tasks like finding similar images or detecting objects.
- Audio Search: We turn audio into a visual representation (audio spectrogram) and use vector embeddings to find similar sounds.
- Recommender Systems: We can make embeddings from structured data about things like products or articles. These are often custom-made for your specific needs. Sometimes, they can also include unstructured data like images or text descriptions.
- Anomaly Detection: By using large datasets of labelled sensor data, we can make embeddings to spot unusual or abnormal events.
Similarity Measures (Distance Metrics)
Similarity measures, also known as distance metrics, in vector embeddings are crucial for many applications in machine learning and data science. They provide a way to quantify how similar or dissimilar two data points are in the vector space. Understanding these measures is essential for tasks such as clustering, classification, recommendation systems, and more.

Here each of these datapoints are mapped into the 2D vector space as illustrated in above image. If you observe carefully, fruits like Apple, Banana and Orange falls within the same region as they belongs to fruit category. Look at their embeddings, they are very close to each other as well. Same goes with category like Veggies and Flowers.
Since human understand these are fruits and needs to be clustered into fruit category. In order comprehend same things by computer / AI we need to measure the distance or similarity of vectors. Now you may ask, how do we measure the similarity or distance between datapoints / vectors? Take a look at below —
- Euclidian Distance
- Manhattan Distance
- Hamming Distance
- Cosine Similarity
These are the commonly used similarity or distance metrics in vector embeddings.
Euclidean Distance (L2):

Let X1 and X2 are two points in 2D space and “d” is the distance between them as shown in the above diagram.

We can find this distance “d” with the help of Pythagoras theorem.

This distance in statistics is known as Euclidean Distance between two points. As for understanding purpose, we took an example of 2D by considering only two features F1 and F2. But in real life, we might have many more features and it is not restricted to two. In such cases, the formula changes. Now we will see how does Euclidean distance behave in d-dimensions.

Note: In both cases in above we have calculated the distance between two and d points. But how do we can represent the same in vector format? After all, every point in dimension can be represented as a vector.

In above equation 2 represents its norm (L2-Norm). As distance is always between two points and the norm is always between two vectors.
Manhattan Distance (L1):
The Manhattan distance between two vectors (or points) X1 and X2 is defined as : →

This is known as Manhattan distance because all paths from the bottom left to the top right of this idealized city have the same distance as shown below

Imagine you are in a city where the streets are laid out in a perfect grid, and you want to travel from the bottom left corner of the city to the top right corner. Unlike in a diagonal straight line (which would be the Euclidean distance), in a grid system like Manhattan, you must travel along the streets, which means moving either horizontally or vertically.
In such a grid, all paths from the bottom left to the top right corner (assuming you only move right or up, without backtracking) have the same length in terms of distance traveled. This is because you’re simply switching the order in which you travel across the grid’s horizontal and vertical lines, but the total number of lines crossed remains constant.
This distance is also noted as L1 -Norm of a vector and it is represented as shown below : →

Hamming Distance:
The concept of Hamming Distance is taken from the Information Theory. It generally used in Text Processing or when the problem statement deals with binary vector or Boolean vector.
We define Hamming Distance in the following way →
Hamming distance between two strings of equal length is the number of positions at which the corresponding symbols are different.
Let’s understand this concept with the help of an example shown below.

Thus the hamming distance (X1, X2) is nothing but the number of location or dimensions where binary vector differs.
Therefore, Hamming Distance (X1, X2) = 3 as it differs in 3 location as shown in the above diagram.
Cosine Distance & Cosine Similarities:
Cosine Distance is based on Cosine Similarities. There is a relationship between cosine similarities and cosine distance that we need to understand first.
“As distance increases, similarity decreases and vice versa.”
So there is an inverse or opposite relationship between similarity and distance. If you think intuitively, as the distance between two points increases which means they are not close to each other which ultimately states these two points are dissimilar.
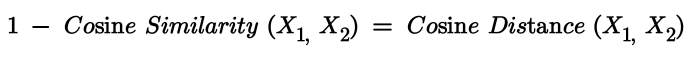
Let cosine similarity lies between [-1, 1] then our cosine distance actually makes sense.
- -1: Dissimilar
- 1: Similar
→ If cosine similarity = 1 then, cosine distance = 1–1 = 0. This actually makes sense as similarity increases the distance reduces.
→ If cosine similarity = -1 then, cosine distance = 1-(-1) = 2. This too make sense as similarity decreases; distance increases.
This is what the relationship between Similarity and Distance that we should aware of. Remember these concepts not just limited to Vector databases but these concepts are heavily used in other areas of machine learning. Now let’s understand cosine similarity in details.

We can find the distance between two given vector i.e. X1 and X2 using Euclidean Distance. Cosine similarity says instead of taking geometrical distance, take an angular distance. In cosine similarity, we measure the degree of angle between two vectors.
Therefore,
Cosine Similarity = Cos θ ….Here θ is the angle between X1 and X2 as shown in the above diagram.

If X1 and X2 are unit vectors then ||X1|| = ||X2|| = 1
Therefore,

If the angular distance between two vectors is more, those vectors are considered as less similar and vice versa.
Vector Indexing
Vector is the method of organizing and managing vector embeddings to enable efficient retrieval, search, or comparison operations.
In short, we can say → Vector indexing is nothing but organizing the similar vectors together.

How Vector Indexing Works
- Storing Vectors: Initially, vector embeddings are created from data (like text, images, etc.). These vectors are multi-dimensional and represent the features of the data.
- Index Creation: An index is built to organize these vectors in a way that optimizes search and retrieval operations. This index can be thought of as a specialized database for vectors.
- Searching the Index: When a query is made (which is also converted into a vector), the indexing system efficiently searches through the vectors to find the most relevant or similar ones.
Now let’s take an example to explain this concept thoroughly.
Example
Let’s consider an example with a text search application:
Dataset:
Suppose we have a large collection of documents. Each document is converted into a vector embedding using techniques like TF-IDF, Word2Vec, or BERT.
Building the Index:
- The vectors from all documents are stored in an index.
- The index might use algorithms like k-Nearest Neighbors (k-NN) or more complex structures like trees or hash tables to organize these vectors.
Performing a Search:
- A user inputs a search query, like “machine learning.”
- The query is also converted into a vector using the same method used for the documents.
- The index quickly searches for and retrieves document vectors that are closest to the query vector in terms of cosine similarity or another similarity metric.
Retrieving Results:
- The documents corresponding to the top matching vectors are retrieved and presented to the user.
- This process is much faster than comparing the query vector to every document vector individually.
Importance of Vector Indexing
- Efficiency: Vector indexing allows for efficient retrieval in large datasets, reducing the search space and computational load.
- Scalability: It makes it feasible to work with very large datasets that would otherwise be impractical to handle.
- Accuracy: By using sophisticated indexing algorithms, the accuracy of retrieval can be enhanced, ensuring more relevant results for queries.
Architecture of Vector Database
The architecture of a vector database is designed to efficiently store, manage, and retrieve high-dimensional vector data, often used in machine learning and data science applications.

Let’s understand this with the help of below pointers →
- Regardless of the content type such as images, emails or text documents, we utilize the embedding model to convert them to vector embeddings.
- These embeddings are then loaded into vector databases where they are efficiently clustered & indexed based on their similarity.
- When the application issues a query, we use the same embedding model to create embeddings for the query and use those embeddings to query the database for similar vector embeddings.
- The vector database performs a search based on the query vector and retrieves the relevant results for the application.
In order to illustrate further consider the below example in IT threat detection application.

We have the activities represented as → Regular, Suspicious and Malicious in vector dimension space. By querying the vector database, we can determine if activity close to regular activity or suspicious activity or malicious activity. This allows us to classify the web traffic based on the proximity to vector space.
If we take the distance between query vector (?) with regular, suspicious and malicious it is evident that the query vector is near to malicious vector. Here query vector is the web traffic. Therefore we can consider the query vector (a web traffic) is malicious one. Therefore, it is like classification or anomaly detection.
So by using the vector database, we can establish common ground a common ground for managing different types of unstructured data and this is why vector database is needed and indeed it is solving the fundamental problem of unstructured data.
How does a vector database work?
In traditional databases, the queries typically aim to find rows where the values exactly match the specified query criteria. On the other hand, in vector databases, the approach is different: we use a similarity metric to identify a vector that most closely resembles our query.

A vector database works by efficiently storing, indexing, and retrieving high-dimensional vector data, which is often used in applications involving machine learning, AI, and big data analytics. Here’s an overview of how it operates.
Step 1 → Data Conversion to Vectors
- Input Data: The data can be of various types like text, images, audio, etc.
- Conversion Process: This data is transformed into vectors using machine learning models. For instance, text can be converted using models like BERT or Word2Vec, images with CNNs, etc. Each vector is a numeric representation of the data, capturing its essential features.
Step 2 → Indexing the Vectors
The main purpose of the indexing is to enable efficient searching within the vector databases. To do this, various algorithm is used to index these vectors which includes —
- k-Nearest Neighbours (k-NN): For finding vectors closest to a query vector.
- Locality-Sensitive Hashing (LSH): For grouping similar vectors.
- Hierarchical Navigable Small World (HNSW): A graph-based approach for indexing.
The indexing creates a structure that makes it easier and faster to search through a large number of vectors.
Step 3 → Query Processing
- Query as a Vector: When a user has a query (like a text query or an image), it is also converted into a vector using the same method as the database vectors.
- Searching: The vector database uses the index to quickly find vectors that are most similar to the query vector.
- Similarity Metrics: The search relies on similarity metrics like cosine similarity, Euclidean distance, etc., to determine the ‘closeness’ of vectors.
Step 4 → Retrieving Results
- Matching Vectors: The database retrieves the data items corresponding to the vectors that closely match the query vector.
- Use Cases: This could be, for example, finding similar images, recommending products, or searching for similar documents.
Step 5 → Post-Processing (Optional)
- Refinement: The initially retrieved results might undergo further processing like re-ranking based on additional criteria or filters.
- Accuracy vs. Speed: There’s often a trade-off between the accuracy of the results and the speed of retrieval. More accurate results might take longer to retrieve.
Example
Imagine a vector database used for a photo search application:
- User Uploads an Image: The image is converted into a vector.
- Database Search: The vector database quickly scans through its indexed vectors to find images whose vectors are most similar to the uploaded image’s vector.
- Result: The user is presented with images that are visually similar to the uploaded image.
In essence, a vector database is specialized in handling complex, high-dimensional data that traditional databases aren’t equipped to manage efficiently. Its ability to rapidly process and retrieve similar items based on vector proximity makes it invaluable in fields like AI and data science.
Enough of the theory now. Let’s get our hands dirty with some practical’s / coding.
Journey of Vector Databases with Pinecone!
Pinecone is a specialized database service designed to efficiently handle vector data, which is commonly used in machine learning applications. This service is particularly useful for tasks that involve searching and comparing vectors, such as in recommendation systems, image recognition, and natural language processing tasks.
Vector databases like Pinecone are crucial in the field of machine learning because they enable quick and accurate retrieval of similar items from large datasets. For instance, in a recommendation system, Pinecone can quickly find products or content similar to a user’s interests by comparing their preference vectors with those in the database.
Pinecone stands out for its scalability and performance, offering high-speed vector search capabilities. This is essential for real-time applications where rapid data retrieval is critical. Additionally, its user-friendly interface and integration capabilities make it accessible for both experienced developers and those new to vector databases.
Environment Setup & Installation
To begin incorporating Pinecone into your GenAI project, the initial step is to set up an account with Pinecone. This can be done by visiting their official website.

After establishing your account with Pinecone, you can proceed to configure your projects and generate the necessary API keys. These keys will be essential for performing various operations and implementing use cases with Pinecone.
As we are utilizing Python to execute operations in Pinecone, it’s necessary to install Pinecone using the ‘pip’ command.
> pip install pinecone-clientFollow official guide on installation → https://docs.pinecone.io/docs/python-client
Hello World with Pinecone
Let’s play with Pinecone database through Python.
# Import Pinecone Library
import pinecone
# Initialize API Key
pinecone.init(api_key="a4345490-b8s9-48e7-8f95-1bce784d353d",
environment="gcp-starter")
# Create an index
pinecone.create_index(name="hello-world",
dimension=3,
metric="cosine") # cosine is default
# check on all the indexes
pinecone.list_indexes()
# This will return ['hello-world'] as output.CRUD with Pinecone!
CRUD operations, which stand for Create, Read, Update, and Delete, are fundamental in managing data in databases or data storage services. When working with Pinecone, a vector database that’s often used for machine learning applications, these operations are adapted to handle vector data. Let’s get started with Create.
Create:

Read:

Update:

Delete:

Concept of Index & Collections
Let’s delve into the crucial concept on an index and collection.
An index in Pinecone is a named collection of vectors. These vectors are essentially high-dimensional data points, typically generated as outputs from machine learning models.
Functionality
- Storing Vectors: An index holds a set of vectors. For example, in an index named ‘test’, which has three dimensions, there are multiple vectors stored within these dimensions.
- Querying: The primary function of an index is to allow querying. You can search through the vectors in an index to find matches or similar vectors based on specific criteria or algorithms.
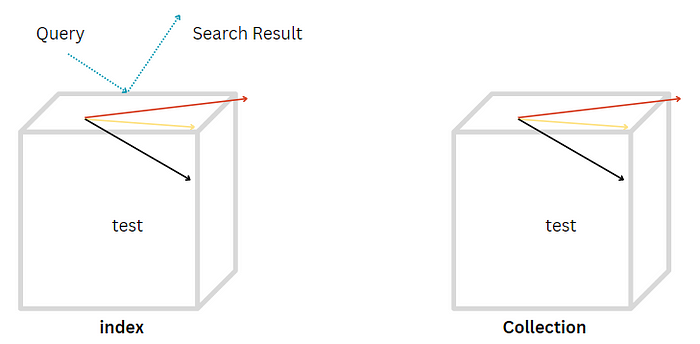
A collection is a static copy of an index in Pinecone. It’s a snapshot or a backup of the state of an index at a given point in time.
Characteristics and Use:
- Static Nature: Unlike an index, a collection is static. You cannot query a collection like you can with an index. It’s essentially a read-only copy of the index data.
- Purpose: The main purpose of a collection is for backing up an index. It serves as a means to preserve the state of an index before making changes.
Managing Index and Collection
We have already seen the concept of Index and Collection above. Let’s get some idea on → How to manage them?
Creating an Index:
You start by creating an index (e.g., ‘test’) where vectors are stored and can be queried.
Modifications and Backup:
- When you need to modify the index (like changing the index type or distance metrics), you first create a static copy of the current index as a collection.
- This backup ensures that the original data is not lost during the transition.
Creating a New Index from Collection:
- You can create a new index with the desired changes (e.g., different index type or distance metrics).
- This new index can be populated with vectors from the collection.
- Multiple indexes can be created from the same collection if needed.
Querying New Index:
Once the new index is set up and populated, it’s ready for querying. The collection remains as a static backup.
Let’s see how index can be managed with Python!
### Import Pinecone Library
import pinecone
### Pinecone Initialization
pinecone.init(api_key="a4345490-b8s8-48e7-8f95-1bce784d353d",
environment="gcp-starter")
### 1. Create an Index
pinecone.create_index(name="crud",
dimension=3,
metric="cosine", # cosine is default
pod_type="s1")
### 2. Retrieve List of Pinecone Database Indexes
pinecone.list_indexes() # --> This will return ['crud']
### 3. Connect to Index
con = pinecone.Index('crud') #We need to describe pointer to connect with Indexes
### 4. Describe the Index
pinecone.describe_index(name='crud')
### This will return below output. Its information about index that you created.
""" IndexDescription(name='crud', metric='cosine', replicas=1, dimension=3.0,
shards=1, pods=1, pod_type='starter', status={'ready': True, 'state': 'Ready'}, metadata_config=None, source_collection='')"""
### 5. Delete an Index
pinecone.delete_index(name='crud')Backing Up Indexes with Collections
As described above, we need Collections to have backup of Indexes. Let’s create Collection first then will move towards creating the backup.
### Step 1 - Let’s create an index
pinecone.create_index(‘test’, dimension=3,
metric=’dotproduct’, pod_type = ‘s1’)
### Step 2 - Lets Create Collection from Index
pinecone.create_collection(name = "my-collection", source = "test")
# You can list all collections from database
pinecone.list_collections() # --> This will return [my-collection]
# Describe the Collection
res = pinecone.describe_collection("my-collection")
res.dimensions # --> It will return 3 as dimension
# Delete the Collection
pinecone.delete_collection("my-collection")
### Step 3 - Continue from Step 2
# Now once you create an collection, you can visit the WebApp to
# create the index from collections.Now once you create an collection, you can visit the dashboard in pinecone WebApp to create index from the created collections.
Vector Partitioning
Vector partitioning is a technique used in database management, especially in systems dealing with large-scale, high-dimensional data such as those found in machine learning applications. It’s particularly relevant for databases that store and manage vectors, which are arrays of numbers representing various features or attributes.
Why Partition Vectors?
Partitioning helps manage large datasets by dividing them into smaller, more manageable segments. This division can improve query performance, enhance scalability, and facilitate better load balancing across the database system.
Consider a database containing emails where each email is represented as vectors for its subject, body, and other metadata.
- Without Partitioning: Searching through this unpartitioned data might be slow and inefficient, especially as the database grows.
- With Partitioning: By partitioning these vectors into different categories (e.g., subjects, bodies), the database can quickly access and search through specific types of data, improving performance.
Methods of Partitioning
- Namespaces:
- Different types of vectors are stored under the same index but categorized into different namespaces.
- With email data, each email is converted into vectors representing the subject, body, and other information. These vectors are then categorized into different namespaces (e.g., subject, body, other) within the same index
2. Separate Indexes:
- Each category of vectors has its own dedicated index.
- Instead of a single index for all email vectors, separate indexes are created for subjects, bodies, and other information.
3. Metadata Tagging:
- Vectors are tagged with metadata to indicate their type or category, still residing in the same index.
- In the e-commerce example, a vector for a shirt might have metadata tags like “category: clothing” and “color: blue.”
- A vector from an email’s subject might have metadata like “data type: subject”, while a body vector might have “data type: body”.
Benefits of Vector Partitioning
- Improved Query Performance: By organizing data into relevant partitions, the system can quickly access the necessary subset of data, speeding up search and retrieval processes.
- Scalability: As data grows, partitioning makes it easier to manage and scale the database across multiple nodes or servers.
- Load Balancing: Distributing data across different partitions or nodes allows for more efficient use of resources and prevents any single node from becoming a bottleneck.
- Fault Tolerance: Partitioning can enhance the robustness of the database by isolating issues within a single partition, preventing them from affecting the entire database.
- Optimized Resource Utilization: Partitioning can lead to more efficient use of storage and processing resources. By organizing data into partitions based on similarity, related data is stored and processed together, optimizing resource use.
Final Note
This extensive article explores vector databases, which are at the core of Generative AI’s growth. we have emphasized the critical role of vector databases in managing complex data structures essential for advanced machine learning models. The article delves into foundational concepts, technological nuances, and the challenges overcome by vector databases.
Key concepts discussed include:
- Vector Databases: These are specialized databases optimized for handling, storing, and retrieving high-dimensional vector data. Unlike traditional databases, vector databases efficiently manage data represented as arrays of numbers (vectors), crucial for AI and machine learning applications.
- Vector Embeddings: This section explains how non-numeric data, like text or images, is converted into vectors that capture meaning and relationships, using algorithms like Word2Vec, GloVe, or BERT for text, and Convolutional Neural Networks for images.
- Similarity Measures (Distance Metrics): The article discusses various metrics like Euclidean Distance, Manhattan Distance, Hamming Distance, and Cosine Similarity, which are used to measure the similarity or dissimilarity between vectors.
- Vector Indexing: It covers how vector embeddings are organized and managed for efficient retrieval, highlighting processes like storing vectors, creating indexes, and searching the index.
- Architecture of Vector Database: The architecture is designed for efficient management and retrieval of high-dimensional vector data, with applications in machine learning and data science.
- Practical Applications with Pinecone: Pinecone is introduced as a specialized database service for handling vector data. The article guides through environment setup, installation, and practical operations in Pinecone, including CRUD operations, managing indexes and collections, and vector partitioning.
- Benefits of Vector Partitioning: The article explains the advantages of partitioning vectors, such as improved query performance, scalability, load balancing, and fault tolerance.
Overall, the article provides a comprehensive understanding of vector databases, their importance in AI and machine learning, and practical insights into using a vector database service like Pinecone.
Please follow me on Medium as more Generative AI content is coming on your way. :)
